Начало работы в Sendsay
Sendsay — маркетинговая CDP для коммуникации с клиентами. Здесь можно:
- создавать и отправлять красивые письма клиентам без ручной вёрстки и программирования,
- следить за статистикой и улучшать показатели,
- сегментировать аудиторию для более точного попадания в ЦА,
- персонализировать письма, подставляя данные клиента в письмо,
- отправлять рассылки в другие каналы — смс, пуш-уведомления, Telegram-рассылки и сообщения во ВКонтакте,
- автоматизировать сбор подписчиков через формы,
- автоматизировать рассылки с помощью триггерных сценариев.
Чтобы зарегистрироваться, нажмите «Регистрация» на сайте sendsay.ru. После создания аккаунта вы попадёте в личный кабинет и получите письмо подтверждения с данными для входа.
В целях безопасности мы просим всех новых пользователей подтвердить номер телефона, привязанный к аккаунту. Прежде чем начать работу, убедитесь, что в вашем аккаунте номер подтверждён: для этого перейдите в раздел Настройки системы → Настройки аккаунта в меню аккаунта.
Для комфортной миграции из другого сервиса рассылок изучите статью Как перейти в Sendsay из другого сервиса рассылок.
С чего начать
Начать работу с email-рассылками в Sendsay можно за 3 простых шага:
1. Добавьте отправителя писем
Для отправки email-рассылок необходимо добавить отправителя писем — имя компании и электронный адрес, с которого получателям приходит рассылка.
По умолчанию система в качестве отправителя писем добавляет email-адрес, на который зарегистрирован аккаунт. Но бесплатные адреса на Mail.ru, Gmail.com и Yandex.ru нельзя использовать в качестве отправителя — это противоречит DMARC-политикам этих доменов и нашей антиспам-политике.
В качестве отправителя можно использовать почту на корпоративном домене формата info@domain.com. Если у вас нет почты на корпоративном домене, можно создать такую в почтовых сервисах для бизнеса — например, Яндекс 360 или VK WorkSpace.
Как создать email-адрес на корпоративном домене
Чтобы добавить отправителя писем:
- В правом верхнем углу нажмите на свой логин и в выпадающем меню выберите Настройки системы. Во вкладке Отправители нажмите «Добавить отправителя».
- Введите имя и адрес.
- На указанную почту придёт письмо подтверждения — перейдите по ссылке из него, чтобы активировать адрес.
2. Добавьте подписчиков
В начале работы система добавляет в базу контактов подтверждённый email-адрес, указанный при регистрации в Sendsay, для дальнейшего тестирования. Отправлять рассылки в Sendsay можно только подтверждённым контактам.
Какие бывают статусы у контактов
Как активировать неподтверждённые адреса
Добавить других подписчиков в базу контактов можно несколькими способами:
- импортировать вручную,
- указать ссылку на файл для импорта,
- собирать через форму сбора подписчиков,
- настроить автоматический импорт подписчиков по расписанию,
- автоматически подгружать из CRM-платформы или по API.
Результаты импорта, как и других действий в системе, можно отследить в Журнале заданий.
Отправлять рассылки можно только тем подписчикам, которые дали согласие на получение писем, — поэтому вся база контактов должна быть собрана вами. Купленные базы и контакты, найденные в свободном доступе, распознаются и не принимаются, либо вас попросят подтвердить, что пользователи оставили свои адреса добровольно.
В случае если вы только зарегистрировались, на бесплатном тарифе вы можете добавить в базу контактов до 200 адресов. Чтобы добавить больше адресов в базу, необходимо выбрать и оплатить соответствующий тариф.
Контакты можно добавлять сразу в список, чтобы разбить базу на аудитории и работать с ними по отдельности. А настройка сегментов позволит учитывать потребности и интересы подписчиков при создании рассылок.
Что такое список контактов
Что такое сегмент контактов
Куда попадают контакты после импорта
Контакты и данные подписчиков хранятся в базе контактов. У каждого подписчика есть свой профиль клиента, где собраны контакты, персональные данные и статистика по получению писем. Посмотреть профиль любого подписчика можно в разделе Подписчики → Просмотр подписчиков, либо с помощью строки поиска — для этого введите адрес контакта:

Каждый клиент может иметь несколько типов контактов в разных каналах — например, email-адрес для отправки писем, номер телефона для отправки смс и идентификатор Web Push-подписки. А каждый профиль клиента может содержать несколько анкет — наборов полей, в которых хранятся персональные данные.
3. Протестируйте отправку выпуска рассылки
Выпуск рассылки — это рассылка (email-письмо, веб-пуш или сообщение во ВКонтакте), отправленная получателям.
Какие бывают виды рассылок
Есть три вида рассылок:
- Массовая — отправляется группе подписчиков, то есть список получателей определён до выхода рассылки.
- Транзакционная — сообщение с персональной информацией, которое отправляется в ответ на действие или запрос пользователя, — например, письмо для восстановления пароля.
- Триггерная — отправляется автоматически после того, как произойдёт заданное условие: например, отп�равить следующее письмо, когда прошло N дней с отправки последнего.
Чтобы протестировать отправку выпуска, создайте шаблон письма:
-
В левом меню перейдите в раздел Контент → Email и нажмите «Создать Email».
-
На шаге Письмо выберите способ, как создать дизайн письма:
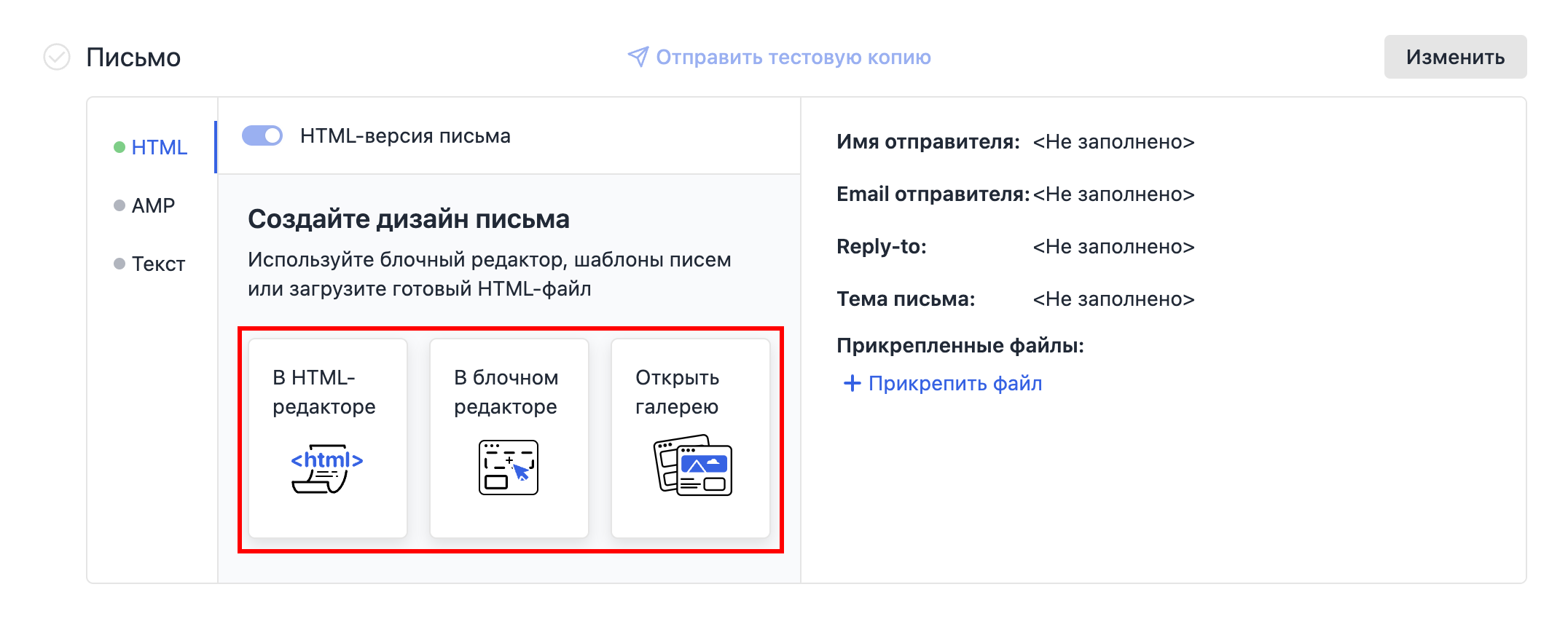
- в конструкторе писем,
- в HTML-редакторе,
- с помощью готового шаблона.
- в конструкторе писем,
-
Отредактируйте и сохраните шаблон, затем на шаге Письмо укажите тему письма, имя и email отправителя.
-
Нажмите «Отправить тестовую копию», введите свой email и нажмите «Отправить».
ВажноОтправить тестовую копию можно только контакту, который есть в базе со статусом Подтверждённый.
-
Проверьте свою почту, — и убедитесь, что письмо отображается так, как вы задумали.
-
Создайте выпуск рассылки из шаблона — для этого нажмите «Создать выпуск». Затем отправьте рассылку.
Выпуски с аккаунтов, с которых ранее ничего не отправлялось, проходят ручную модерацию: наши специалисты смотрят, удовлетворяет ли выпуск требованиям антиспам-политики Sendsay.
Почему выпуск попал на модерацию
Как отменить или приостановить отправку выпуска
После отправки рассылки показатели можно посмотреть в разделе Статистика.
Где следить за статистикой
Всё про статистические отчёты
После того как вы убедитесь, что всё работает именно так, как вы ожидаете, подключите домен и настройте email-аутентификацию для дальнейшей работы. Вы можете сделать это как самостоятельно, так и заказать полную настройку у специалистов Sendsay — для этого .
Как подключить домен и настроить email-аутентификацию
Из чего состоит email-аутентификация
Что дальше
Автоматизировать работу с рассылками в Sendsay можно с помощью:
– сценариев,
– автоматических рассылок по расписанию.
Помимо email-писем, в Sendsay вы можете отправлять:
– смс,
– мобильные пуш-уведомления,
– веб-пуши,
– сообщения во ВКонтакте,
– рассылки в Telegram через бота.
Также есть готовые интеграции с другими системами:
– Tilda,
– Bitrix24,
– amoCRM,
– Email on Acid.
Рассылки необязательно создавать в интерфейсе Sendsay — с помощью Sendsay API можно настроить интеграцию с любой системой.